Is PostgreSQL the Only Vector Database You Will Ever Need?
PostgreSQL provides pgvector extension, an efficient extension for LLM-based applications to replace costly dedicated vector databases.


There was a phase not too long ago when sequential databases got a bad reputation for being too rigid. Companies and developers started flocking toward the NoSQL alternatives like MongoDB and Cassandra thinking they were the ultimate solution to all their database-related issues. However, now that the dust has settled and the cracks in NoSql databases have started to show, relational databases are gaining back their lost reputation.
There are a plethora of sequential databases you can choose from. However, In recent times LLMs have gained popularity and most companies or applications are in a race to incorporate LLM-based features. This means working with data that has thousands or millions of dimensions. Can normal SQL databases handle that or is there another solution? Is having a dedicated database to handle these vectors worth it? We will talk about all these things in this article but first, let's just talk about why we think PostgreSQL is an overall strong database solution.
Distinct features of PostgreSQL
Here is a comprehensive list of features that make Posgres an overall strong candidate for you.
- Postgres is completely ACID (Atomicity, Consistency, Isolation, and Durability) compliant, as it handles transactions consistently and reliably and maintains data integrity even in the case of failures. Furthermore, the MVCC (Multi-Version Concurrency Control) allows multiple transactions to occur at the same time which allows high concurrency.
- It offers user-defined functions (UDFs) with multiple language support, which allows users to customize logic directly in the database. Moreover, users can define their own data types and functions which makes it highly extensible and flexible.
- Postgres enables the use of several complex data types like arrays (for storing multidimensional data), JSON/JSONB (great for semi-structured data like NoSQL), Hstore (for unstructured data), and through PostGIS extension, you can store Geospatial data too.
- It has support for advanced SQL features like window functions, common table expressions (CTEs), recursive queries, and full-text search.
- As Postgres is open source, it has no licensing restrictions, which means it is cost-effective for businesses of all scales. Moreover, as an established database, it has a big community that makes sure it keeps up with the contemporary requirements of a database.
- One catch was that Postgres did not have native vector capabilities. However, the pgvector extension is meant to fill this void.
Here is a pictorial comparison of how your architecture will look based on whether you are using PostgreSQL (which can efficiently replace all these components) or not.
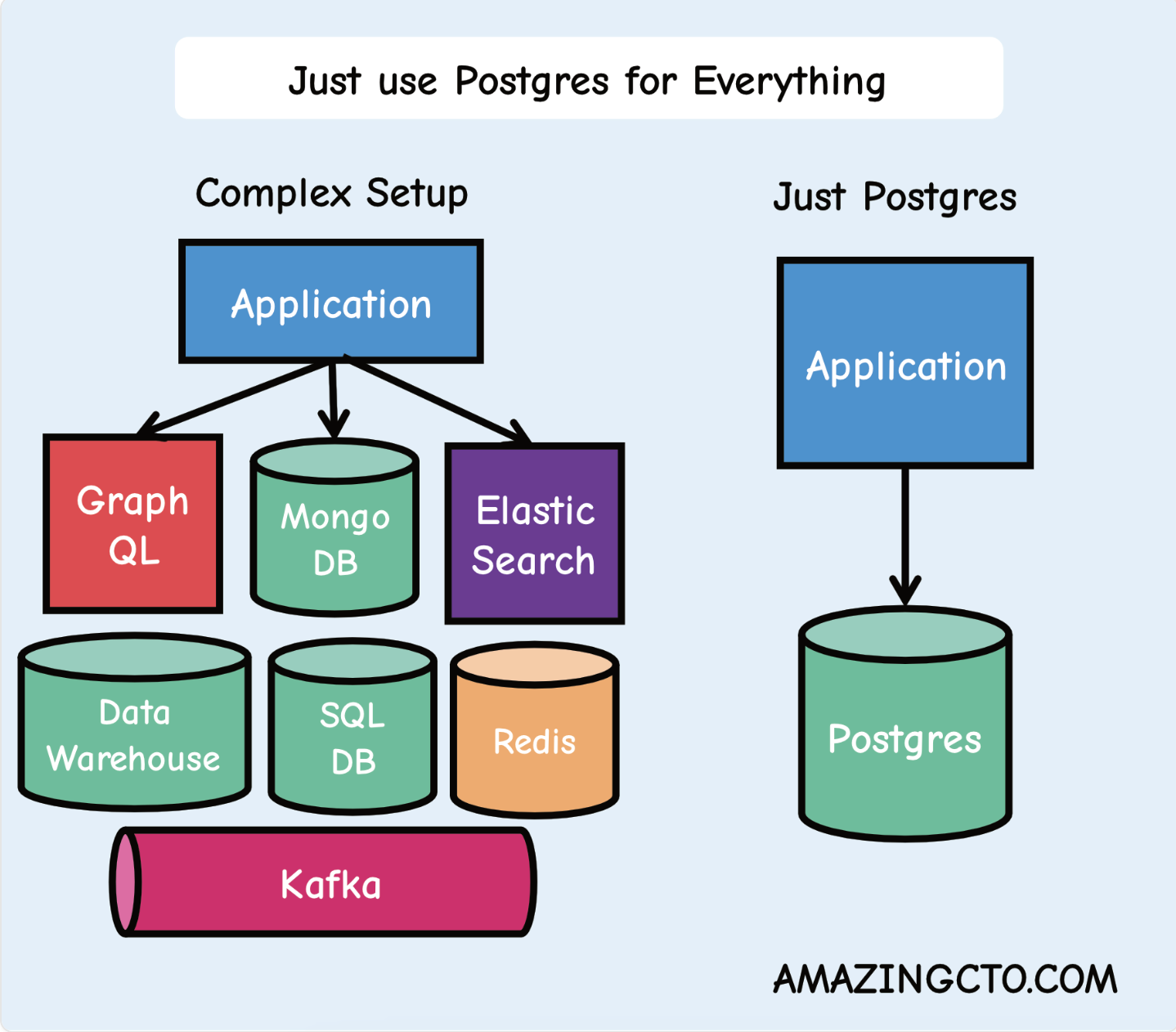
However, the question we all might ask here is whether Postgres pgvector is the silver bullet for all your vector database problems or not. Is this really the only database you will need? Let’s take a deep dive into what vector databases are and if the pgvector search and query functionalities are as good as a dedicated database.
Why do we use vector databases?
As mentioned at the start of this article, when working with AI-based models, you need to generate embeddings, which are a vector representation of text. The vectors range from hundreds to in some cases up to millions of dimensions. Vector databases are used primarily to manage and search through high-dimensional data, often in the form of embeddings or feature vectors. These vectors are typically generated by machine learning models to represent complex objects like text, images, audio, or other forms of unstructured data in a way that captures their semantic meaning or similarities.
As in these cases, the classical search (which looks for an exact match) does not work. There might be no exact match for a question like “How efficient is querying in Postgres using the pgvectore database?” That is why we need a semantic search in these cases (a method to search for data that is close to each other in context and meaning).
If you want to understand embeddings better head up to open-source embedding models.
Do vector databases deliver on their promise?
So, do vector databases provide any value for your LLM-based applications, or how do they work? One thing is certain it is not feasible to query a database without using a database that is designed to deal with vectors. However, when we talk about organizational-level AI generation applications, we are talking about complex architectures and multi-component tech stacks. There is a huge number of API endpoints, development languages, frameworks, teams, and tons of data of different types involved.
Now, you want to build an LLM-based application (that is highly context-dependent) that is oblivious to all this data. To solve that problem, technically there are three pathways you can take from here, but realistically you have only two solutions either to fine-tune your data or to use RAG. As retraining is not an option for you if you don’t have clean datasets, millions of dollars, and access to multiple GPUs. Moreover, fine-tuning is also a solution that is quite a behavior and model-specific. It leaves us with one option, to build the LLM-based application using a RAG-based system. Here is how RAG-based systems work and why a database that can handle vectors is needed:
- In this system, the first step is to convert the documents (or other types of data) into vector embeddings. These are high-dimensional numerical representations of the text that capture its meaning.
- When a user asks a question, the system converts the query into a vector embedding as well.
- Then, it searches for the most similar vectors (i.e., documents) in the database using vector search. This is where vector databases come in. They are designed to store and efficiently search through large collections of vector embeddings, allowing the system to find the most relevant documents quickly.
Suggested Article: Generative AI models for businesses
What are the challenges you face with using vector databases?
Now, we might ask ourselves whether it is feasible to introduce a new component to an already complex architecture. Additionally, is it the only problem? Here are some of the problems that might arise while working with a vector database.
- Many organizations already have a well-established database infrastructure that manages critical data. Integrating a vector database into such a system can be complex and requires custom integrations.
- Converting data into vector embeddings, as well as properly indexing and storing the embeddings in a vector database requires the creation of additional data pipelines. This can add overhead to the system.
- These databases can only be used to manage vectors so you will need to fetch and process all other kinds of data like Binary, JSON, etc separately.
- Using a vector database often introduces data duplication because organizations may need to store the same data in both their primary database and the vector database (as embeddings). This can lead to higher storage costs and complexity in data management.
- Keeping vector embeddings in sync with the original data (e.g., text, images, etc.) can be tricky, particularly when the underlying data is updated frequently.
- Storing high-dimensional vectors can be storage-intensive. This can significantly increase operational costs.
Hence, it is evident that not only does introducing a dedicated vector database add up cost and bring in added complexity but there are other problems as well. So, what can we do to deal with this?
Why can the PostgreSQL pgvector extension be a great alternative?
PostgreSQL now has a pgvector extension that allows you to do everything a regular vector database does. You can search in pgvector or query the pgvector like other dedicated vector databases. One of the biggest advantages of pgvector is that it is an extension of PostgreSQL so you do not have to go through the hassle of incorporating and configuring a new database into your code architecture.
Moreover, PostgreSQL is capable of handling all kinds of complex data types and in addition to vector indexing, it allows B-tree indexing for scalar columns. It means you can combine both non-vector and vector search features in a single query. For example, you can filter based on certain attributes and then perform a similarity search on the resulting subset of data. It is highly applicable in several real-world applications.
Now if we talk about features and stability, PostgreSQL is one of the most reliable and suitable database systems available. There is a large active community behind this database with several libraries, tools, and resources. By using pgvector, you benefit from the vast ecosystem of PostgreSQL tools for backup, performance monitoring, security, etc. The fact that this database is completely open-source is what makes it cost-effective for businesses as well, where you get to use state-of-the-art features without having to break the bank.
The only question is, how does it compare to the performance of regular vector databases? Are there any trade-offs? Dedicated vector databases like PineCone or Qdrant are optimized for extremely large-scale applications. On the other hand, pgvector is more suitable for medium to large-sized vector search workloads. However, if you are not dealing with billions of vectors then pgvector can be scaled efficiently to meet your needs.
How do we at Codesphere integrate pgvector extension in our projects?
At Codesphere, we have recently built several projects for our customers, with different levels of complexity for each one. While dealing with these AI-based solutions we were juggling with data that was not very clean or in most cases enough to fine-tune any models. Hence, we decided to go with RAG-based systems, and using a vector database was our only choice. So, we tried and tested multiple vector database solutions. We started off with Qdrant but switched to pgvector extension, mostly because it is more flexible and capable and there is a huge community behind it where you can find plenty of resources regarding potential issues you might run into.
We are also devoted advocates for open-source technologies so it fits right in with our general preference for software technologies. Moreover, it is a huge upside when you consider the cost of the project. One of the biggest reasons we chose this solution was how cost-efficient it was without any performance trade-offs. We are currently using it for multiple classic RAG cases like for building chatbots, live transcription applications, and a document comparison tool. If you are interested in knowing exactly what we worked on, head over here to read more about an application we created for our customer using pgvector.
Suggested Reading: Self-hosted AI