Digitizing Processes Made Easy: LLM + Low Code Workflow on Codesphere
Low Code automation safes time and money. This Tutorial showcases the potential of low code solutions on Codesphere.


Automating tasks with a Large Language Model on Codesphere is straightforward, even for those with minimal coding experience. You can save on development time and costs by utilizing low-code automation tools like n8n, which can be self-hosted on Codesphere.
To demonstrate low-code automation on Codesphere, we'll create a News Bot. This bot will post a weekly summary of the top 10 trending AI models from Hugging Face on a Discord server. We'll achieve this by utilizing the Hugging Face API to fetch the trending models and employing a self-hosted Large Language Model (LLM).
Prerequisites
For this task, we'll together set up an n8n instance, a self-hosted Llama.cpp instance, and a basic Flask app. You need to create 3 workspaces in total:
- Codesphere Account: Sign up
- n8n instance: n8n Tutorial
- workspace with the Flask app (Free plan): Git-Hub link
- llama.cpp-python endpoint workspace: llama2 + API template + YT-Tutorial
n8n workflow
You can locate a copy of the workflow in our GitHub repository, available in the n8n starting guide: [n8n Tutorial]. If you already have an n8n instance on Codesphere, simply pull the repository. If you don't have an n8n instance yet, create a new workspace using this GitHub link.
https://github.com/codesphere-cloud/n8n-TemplateGitHub link for creating a n8n instance
Next, download the HuggingFace.json workflow file to later import it into your own workflows. You can find instructions on how to do this here. The provided workflow corresponds to the one discussed in this article:
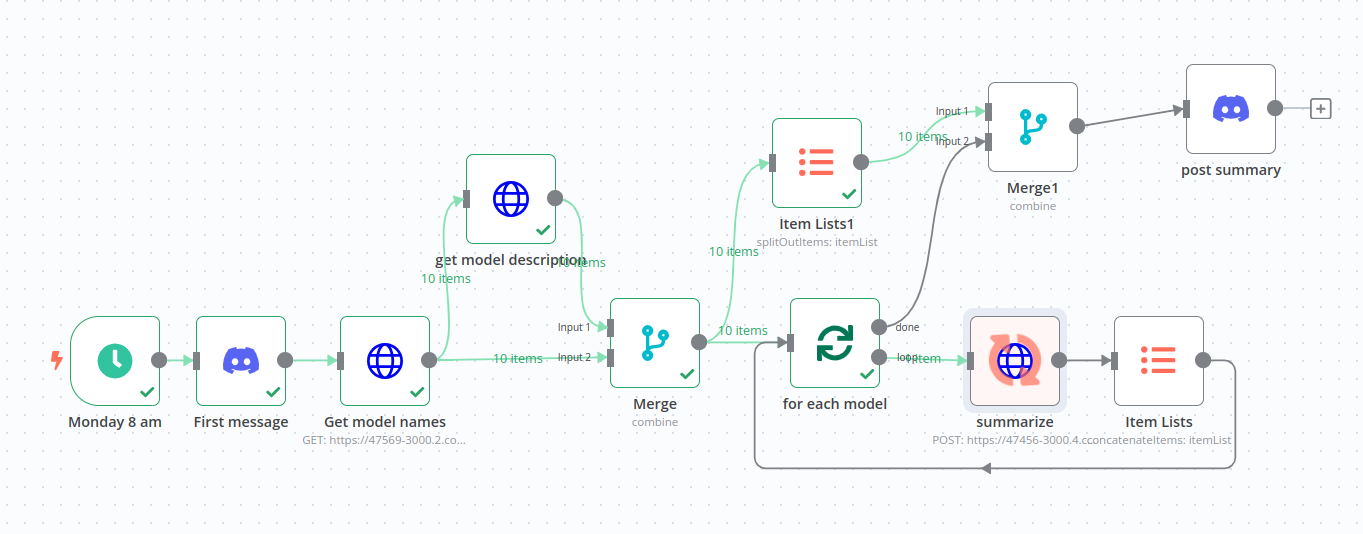
Next, we'll set up the workflow together.
Discord Webhook
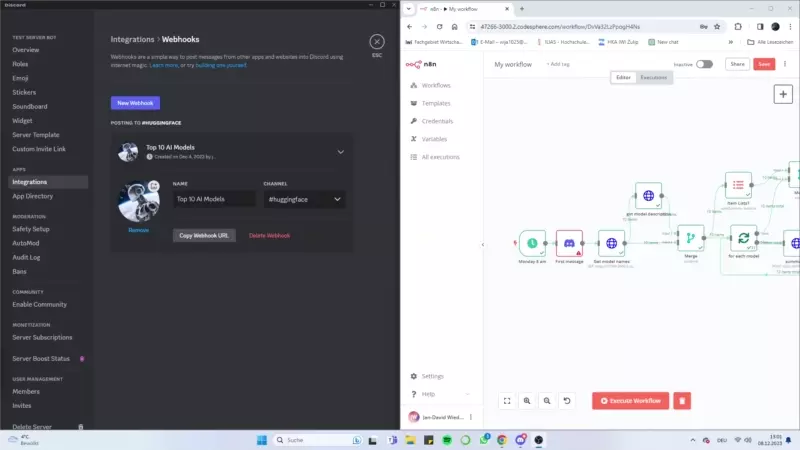
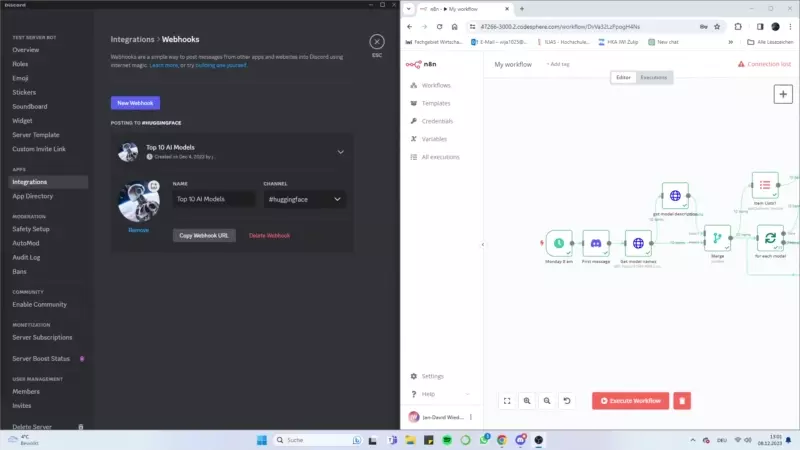
To post the summary of the model cards on one of our Discord servers, create a new Discord Webhook and paste the generated Webhook URL into the corresponding fields. Instructions on generating a new Webhook can be found here.
Insert the Webhook URL into the two Discord nodes on n8n to enable the posting of messages on Discord.
Flask app
Flask is a lightweight and web framework written in Python. It is designed to be simple and easy to use, making it a popular choice for building web applications and APIs (Application Programming Interfaces) in Python.
In this workflow we use a Flask app to scrape the model cards of the top 10 trending AI models on Hugging Face when accessing the API endpoints: trending models.
For this Flask template you can use a free plan. Just create a new workspace using this GitHub link:
https://github.com/codesphere-cloud/flask-app-HuggingFaceGitHub link for the Flask app.
Here you can see how to create a new workspace and clone a Git-Hub repository in one simple step on Codesphere:
When you created a workspace which contains this Flask project, the only thing you need to do is to hit the 'prepare' and 'run'-stage of the CI-pipeline.
Afterwards we need to set up the HTTP-request nodes on n8n which utilizes the API of this Flask app. For that you need to copy your workspace-URL of the Flask app and paste it in the URL field.
In the get model namenode you need to append /get_trending_modelsto that URL.
In the Get Model Descriptionnode, append /get_model_card to the URL. Additionally, set up a query string in the URL that contains information about the model you want to access. Now, append ?model_name= to the URL.
Lastly, drag and drop the model name, which we scraped in a previous node, into our query string. This will serve as a placeholder for every model we scraped, and this query will be performed for every set of 10 models:

In the Flask app, we've limited the maximum number of scraped words to 200. Adjust the word count by modifying the value in line 80:
model_card_content_first_200_words = ' '.join(words[:200])
Line 80 in app.py
Llama.cpp Python API
For the LLama.cpp instance, we recommend using either a Pro plan or a shared-GPU plan to ensure optimal performance for the Large Language Model (LLM). Simply use the Llama2 + API template provided in the create workspace interface.

When starting the prepare-stage of the CI-Pipeline, it takes a few minutes to download the entire model to our workspace. In this workflow, we are using the SlimOrca-13B-GGUF model in the GGUF format:

Feel free to select different models, and we suggest using the GGUF format for the best results.
To configure the HTTP request to our self-hosted LLM in the n8n workflow, simply copy and paste the workspace URL form the llama.cpp instance into the summarize node. Then, append /v1/completion to the URL. Since this HTTP request needs to be a POST method, include a JSON request body representing the prompt for the summarization task.
{
"prompt": "\n\n# Instructions:\nplease provide a bullet point summary. Print before every bullet point a new line but as escaped character. Furthermore just provide up to 3 bullet points. each bullet point must start with *. This is the structure for your output: ## Modeltype\n*(bulletpoints)\n## Summary\n*(bulletpoints)\n\nin the following section is the text to analyse:\n{{ $json.text }}\n\n# Response: in the following i will summarize the model card of the model {{ $json.name }}:\n",
"stop": [
"\n##Evaluation",
"\n##Model Details",
"\n##Applications",
"\n##OutofScope Use Restrictions",
"\n##Research Applications",
"\n##license",
"\n##model sources",
"\n##User Study",
"\n##excluded uses",
"\n###Links",
"\n###Usage"
]
}The prompt in JSON format.
You can customize many aspects in the prompt. Click 'Open Deployment' in the top right corner of the llama.cpp workspace and add /docs to the URL for API documentation, where you'll find details on prompt configuration.

We utilized the prompt section to define the prompt's context. While you can stick with the default prompt in this workflow template, we encourage you to experiment and customize it as needed.
Result
With everything set up, you can now activate your workflow. The workflow is scheduled to trigger every week at 8 am. If needed, you can adjust this schedule in the node:
When triggered, this workflow initiates two HTTP requests to our Flask app, overseeing the scraping of AI model cards through the official HuggingFace API. During the data scraping process, we preprocess the text by removing unnecessary stopwords. This step is taken to eliminate redundant information that adds no value to the context and only occupies unnecessary space.
After collecting this data, we can now feed the preprocessed text into our LLM using our prompt. The workflow loop iterates through all 10 AI models, resulting in a summary for each model. This loop can take a couple of minutes, depending on the size of the prompt.
Finally, we send these results to our Discord Webhook as embeds, ensuring that the summary of each AI model is posted in a dedicated channel within our Discord server:

This workflow serves as a demonstration of the possibilities achievable through low-code solutions on Codesphere. By seamlessly integrating various tools and technologies, we've showcased how you can automate complex tasks efficiently.
Explore the potential of these tools, experiment, and simplify the development process with Codesphere.
Discord Community Server
If you want to connect with fellow Codesphere users and developers you can join our Discord Community Server: https://discord.gg/codesphere