Efficient Document Comparison for Compliance Using AI and Embeddings
AI-powered system for comparing internal documents with regulations using embeddings, chunking, and local LLMs. It avoids keyword matching pitfalls by understanding meaning, storing vectors in PostgreSQL with pgvector, and generating contextual insights

With today's rapid-paced regulatory environment, sustaining compliance within intricate documents is more important than ever. Particularly in highly regulated industries, ensuring that internal documents meet changing standards is an ongoing challenge. Human compliance checks remain prevalent but slow, error-prone, and unscalable.
Fortunately, contemporary Natural Language Processing (NLP) methods provide an incredibly effective solution. Rather than having to compare thousands of rules manually, we can now represent documents as mathematical structures that retain meaning. These structures, embeddings, enable semantic comparisons and analysis between documents, rather than syntactic ones.
This article describes a system which employs:
- Embeddings to compare semantically
- Chunking to handle and organise lengthy documents
- PostgreSQL + pgvector for storing and querying vector data
- Semantic Search – Matching of Chunks
- Prompted LLMs for compliance assessment and recommendations
Let's start by knowing the issue this system is meant to address.
The Problem in Simple Terms:
Suppose there are two sets of documents:
- One is regulatory requirements (e.g., EU regulation, external guidelines)
- The other is internal documentation (e.g., process guides, policy documents)
The goal is to automatically identify whether the internal content is compliant with regulatory requirements. This entails:
- Interpreting the meaning of each regulatory requirement
- Identifying corresponding or missing content in internal documents
- Suggesting updates where there is a lack of alignment
This is not mere keyword matching, it's about meaning, nuance, and context.
Why Keyword Search Isn't Enough?
Here are two sentences:
A: "Banks have to report significant cyber incidents within 24 hours."
B: "Institutions should report severe digital outages to the authorities within a day."
They convey the same requirement but with entirely different words. A conventional keyword search would probably treat them as unrelated since it searches for exact word matches, not meaning.
This is where semantic embeddings enter the picture: they capture the meaning behind the text, not the surface-level words.
Step 1: Embeddings — Translating Text Into Meaning You Can Quantify
Once we know keyword matching doesn't cut it, we need something that can help us grasp what the text is about, not necessarily how it is written. This is where embeddings step in.
What Are Embeddings, Really?
An embedding is a numbers list that captures the meaning of a piece of text. They're created by big neural networks given billions of words, and their task, put simply, is to ensure similar meanings have similar vectors.
So rather than comparing words, we're comparing these vectors to determine if the concepts within two pieces of text match.
Think of It Like This:
Imagine that each sentence is a small object floating in space. But not in 3D space, this is a high-dimensional space (typically 768 to 1536 dimensions, depending on the model).
- Similar sentences wind up floating near one another.
- Sentences with distinct meanings float far away.
Example:
The first two vectors are almost identical, they encode the same intent in different words. The third vector, though, is far apart because it's about something unrelated.
How Do We Measure the Similarity Between These Vectors?
Answer is Cosine Similarity.
To measure how similar two vectors are in this space, we use cosine similarity. It doesn't measure the raw distance between the two vectors, but rather the angle between them.
- Small angle → vectors are pointing in the same direction → high similarity
- Large angle → vectors are moving away → low similarity
What It Looks Like When Texts Are Similar:
If the cosine of the angle is approximately 1, we can assume the meanings are probably in alignment.
This is the underlying method behind semantic search: rather than matching literal words, we're matching the intent and context baked into these math embeddings.
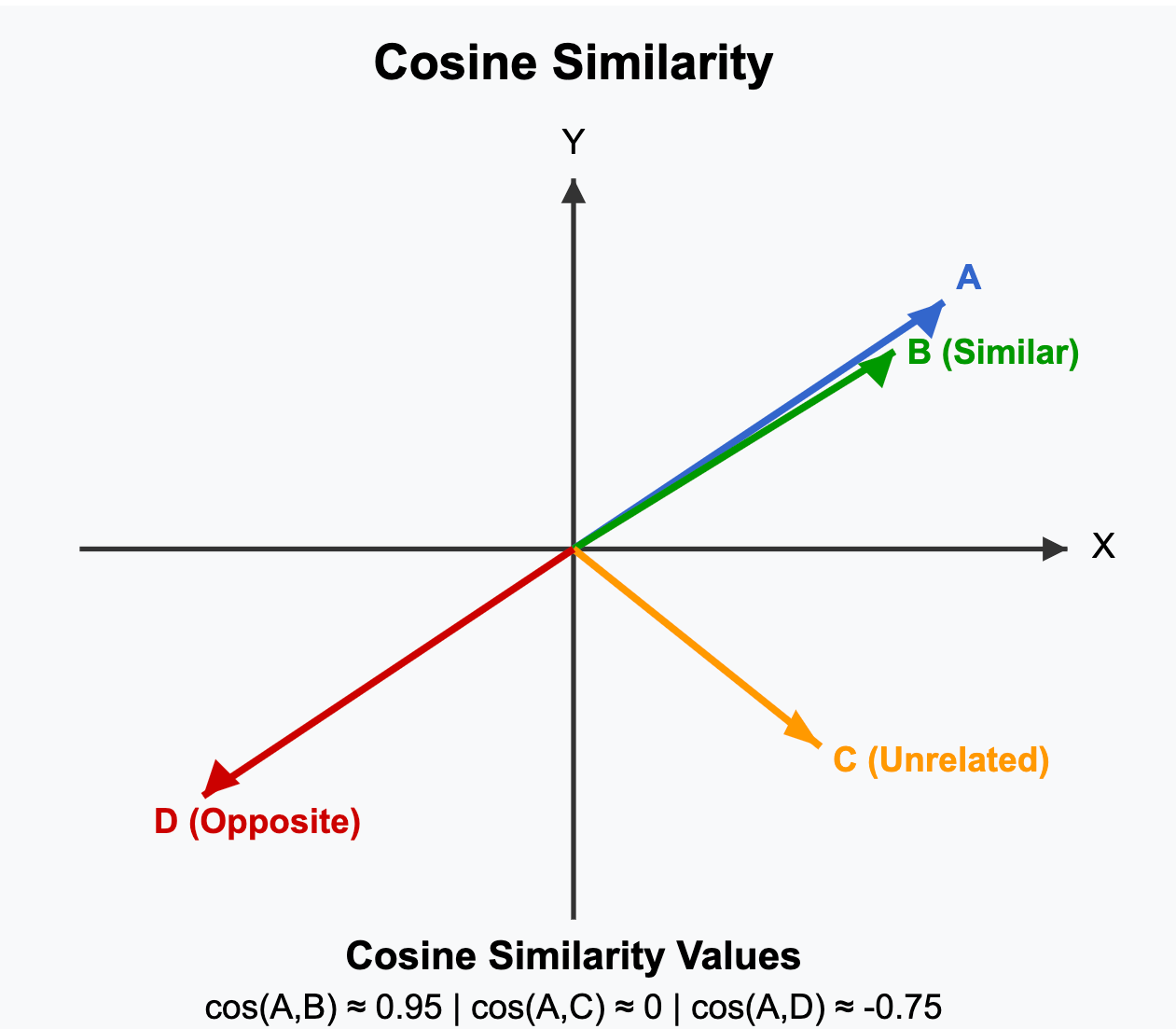
If two embeddings point in nearly the same direction, the angle is small, and the cosine is high = strong match.
Step 2: Chunking – Structuring Documents for Precision
Before comparing content meaningfully, documents need to be broken down into smaller parts. That’s where chunking comes in.
Why Not Use the Whole Document?
Entire documents are too broad and messy for meaningful comparison. Without structure:
- Specificity is lost
- Matching is inefficient
- Context is too diluted
What Is a Chunk?
A chunk is a small, self-contained unit of text, such as a clause, paragraph, or bullet point.
Example:
Full Document:
"Banks must implement resilience protocols. All incidents must be reported within 24 hours..."
Chunks:
[1] "Banks must implement resilience protocols."
[2] "All incidents must be reported within 24 hours."
Each chunk is embedded separately, enabling fine-grained comparison.
Chunking Details
- Typical size: 500–2048 tokens
- Overlaps (sliding windows) maintain context
- Metadata is stored per chunk (source, position, etc.)
Why Does This Matter?
Chunking takes an expansive, open-ended document and turns it into a collection of well-defined, bite-sized pieces. This not only makes semantic search more precise, but also translatable when presenting results to people or when seeding an LLM.
Step 3: Saving and Retrieving Embeddings – PostgreSQL + pgvector
After embedding chunks into vectors, they must be stored and retrieved efficiently, that's where PostgreSQL and pgvector come in.
Why a Vector Database?
Embeddings are high-dimensional vectors (e.g., 768 dimensions), and we must:
- Store thousands (or millions)
- Query the most similar ones (fast nearest-neighbor search)
- Filter by metadata (e.g., document type, date, section)
Instead of having a dedicated vector database, we can add vector support to a regular relational database.
pgvector:
pgvector is a PostgreSQL extension that allows you to:
Store vector columns in tables (vector(768))
Execute fast similarity search with cosine, L2, or inner product
Merge semantic and classic filtering in one SQL query
How It Works in Practice?
Each chunk is stored like this:
And querying like this using the L2 distance operator (<#>):
SELECT content, source_doc
FROM chunks
ORDER BY embedding <#> '[0.22, 0.88, 0.13, .]'
LIMIT 5;This returns the top 5 chunks that are semantically closest.
Step 4: Semantic Search – Matching of Chunks
After both regulations and internal content are chunked and embedded, they can be matched with vector search.
Regulation ➜ Most Similar Internal Chunks
A regulation clause is embedded, and the system fetches the most similar internal chunks by cosine distance:
SELECT chunk_id, chunk_text
FROM internal_chunks
WHERE vector <=> :regulation_vector < 0.5
ORDER BY vector <=> :regulation_vector ASC
LIMIT 5;
- <=> is the cosine distance operator (through pgvector)
- Results returned in most-to-least similar order
Match Quality Thresholds:
- ≤ 0.20 ➜ high chance of being compliant
- 0.20–0.5 ➜ could be related
- > 0.5 ➜ unrelated or non-compliant
These results are then carried through to the next stage.
Step 5: Provoking LLMs – Converting Matches to Assessments and Recommendations
Once candidate matches have been discovered through embeddings, the subsequent challenge is knowing whether or not those matches actually satisfy the regulation—and what to do if they don't.
This is where large language models (LLMs) come in.
🔍 The Role of LLMs
Instead of trusting in fixed rules or similarity measures alone, LLMs can reason across the matched text. They take language, tone, intent, and gaps into consideration—just like a human examiner would.
We are requesting two major things from the model:
1. Assessment Prompt – Is This Good Enough?
This prompt verifies whether any of the internal chunks found satisfy the regulatory clause.
Example Prompt:
"Here's a regulatory requirement:
'Authorities should be notified within 24 hours of a cyber incident.'
And internal policy snippets like these:
• “We provide incident reports monthly.”
• “Cyber incidents are tracked internally.”
Do any of them meet the requirement? If not, why?
The model considers adequacy, gaps, and relevance.
2. Recommendation Prompt – How Can It Be Improved?
If the answer is "no," the model is then prompted to propose actionable revisions or additions.
Example Prompt:
"Considering the need and the existing internal policy, how do you revise the content to be in complete compliance?"
It could answer:
"The policy should dictate that authorities should be informed within 24 hours of any notable cyber incident, not merely recorded internally."
Why Not Skip This Step?
You may ask: can't we simply use cosine similarity? Or a rule-based checklist?
Here's why LLMs are necessary:
- Embeddings tell you what's similar—but not why.
- Rules disintegrate in complicated, real-world wording.
- LLMs offer nuance, explanation, and natural language generation.
System Architecture
To build this system, a few key tools are needed for chunking, storing, retrieving, and analyzing the data efficiently and locally.
Components
- FastAPI – Backend orchestration and API logic
- Svelte – Frontend interface and compliance dashboard
- PostgreSQL + pgvector – Stores text chunks and their embeddings
- LLaMA.cpp – Runs LLMs locally for private inference
- Prefect – Manages pipelines and task execution
Trade-offs:
There are trade-offs even with robust automation:
- Chunking lacks nuance if boundaries are misaligned
- Embeddings match irrelevant content
- LLMs can misread or overgenerate
- Setup takes compute and storage
- Assessments still require human checking
Conclusion:
This system demonstrates how to build a scalable, LLM-enhanced document comparison pipeline that can be adapted for any regulatory or compliance task. By leveraging semantic embeddings, vector search, and local LLM inference, the solution provides precision, transparency, and efficiency without the need for cloud-based AI infrastructure.
Such a configuration can be used across industries wherever documents have to be mapped, compared, or aligned semantically, ranging from regulatory audits to contract analysis and policy alignment.